

Содержание
Введение
В интернете находится более миллиарда сайтов. Правильно подобранные ключевые фразы для семантического ядра помогают пользователям видеть ваш сайт, будь то контекстная реклама или органическая выдача.
О том, как подобрать те самые слова и фразы и правильно работать с «Яндекс Wordstat», рассказывают Светлана Кабалина, медиапланер, и Александра Иванова, SEO-специалист Webit.
Сегодня со Светланой Кабалиной медиапланером Webit и Александрой Ивановой SEO-специалистом Webit поговорим об одном из инструментов — Яндекс.Вордстат, и расскажем о том, как правильно с ним работать.
Что такое Яндекс Вордстат?
Мы каждый день ищем информацию в поисковых системах, вбивая в поисковой строке интересующие запросы. Какие-то запросы ищут часто, и они обладают высокой частотностью, а какие-то менее популярны, это низкочастотные запросы.
Определить частотность помогает бесплатный сервис Wordstat Yandex, в котором можно наглядно увидеть статистику запросов.
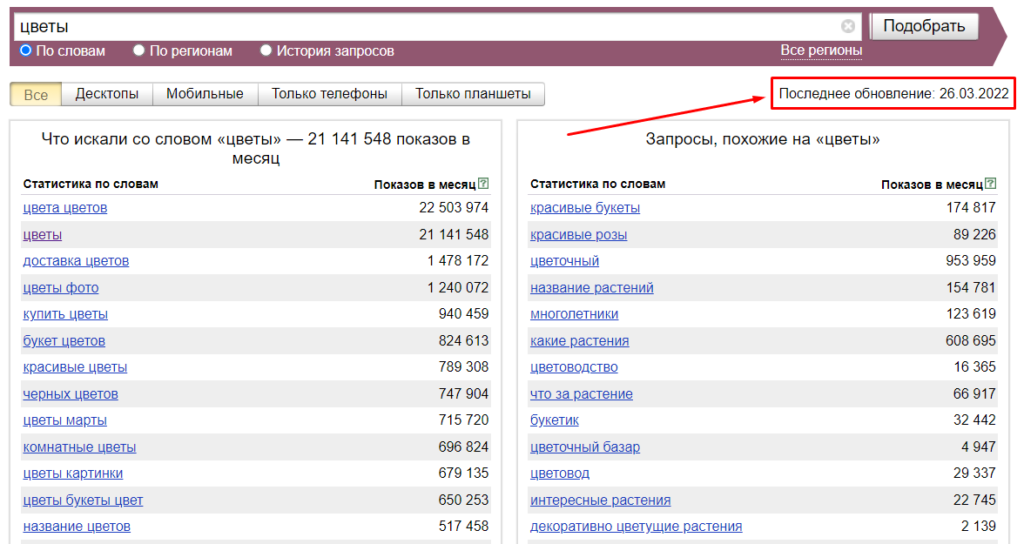
Числа рядом с каждым запросом показывают сколько раз этот запрос искали пользователи за последние 30 дней от указанной даты обновления.
Почему необходимо знать Вордстат?
Грамотному специалисту или владельцу бизнеса необходимо знать, как работать с Вордстат Яндекс, потому что этот инструмент позволяет быстро и с высокой точностью решать многие стратегические и оперативные задачи, которые возникают в каждом бизнесе:
- определить сезонность ключевой фразы;
- сформировать семантическое ядро для сайта;
- оценить и изучить интерес пользователей к определенной теме;
- прописать анкоры для ссылок;
- спрогнозировать потенциальный трафик на сайт;
- подготовить список фраз для запуска контекстной рекламы в сервисе Яндекс.Директ;
- проанализировать географическую популярность запроса.
Как правильно работать с Wordstat?
Изучаем интерфейс
Первое, что необходимо сделать перед использованием сервиса — зарегистрировать аккаунт:
Теперь давайте рассмотрим на примере кейса, как пользоваться Вордстатом. Для этого представим себя начинающим предпринимателем, который собирается погрузиться в цветочный бизнес. Начнем с простой фразы «купить букет».
Вписываем в строку интересующий запрос:
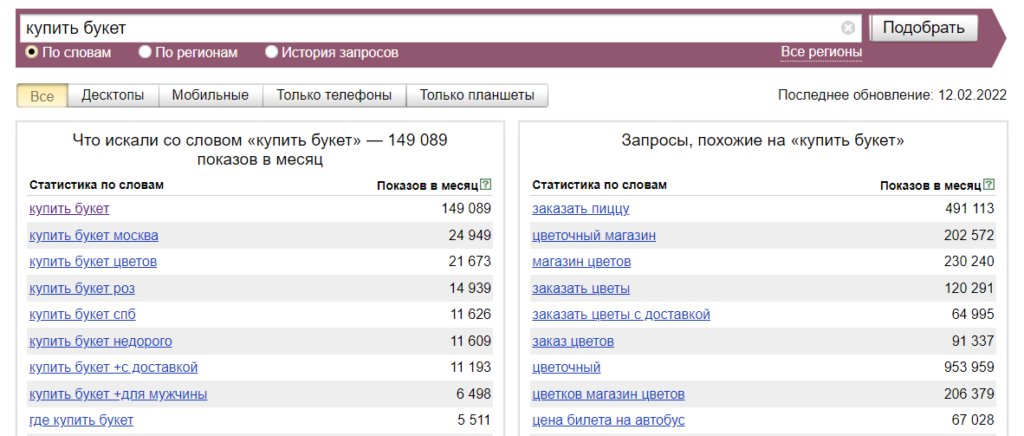
В левом столбце «Что искали со словом…» мы видим, что запросом «купить букет» — интересовались 149 089 раз за месяц. Неплохой спрос, правда?
Но не все так однозначно. Это количество включает в себя не только запрос «купить букет», но и все, расположенные ниже: «купить букет москва» (24 949 показов), «купить букет цветов» (21 673 показов), «купить букет роз» (14 939 показов) и т.д.
Правая колонка показывает, чем еще интересовались люди, вводившие нужный нам запрос. Там отображаются фразы, которые по теме похожи на введенную, но содержат другие слова.
Что же тогда делать, если нужно узнать спрос именно на фразу «купить букет»? Об этом поговорим чуть ниже, после того, как закончим знакомство с интерфейсом сервиса.
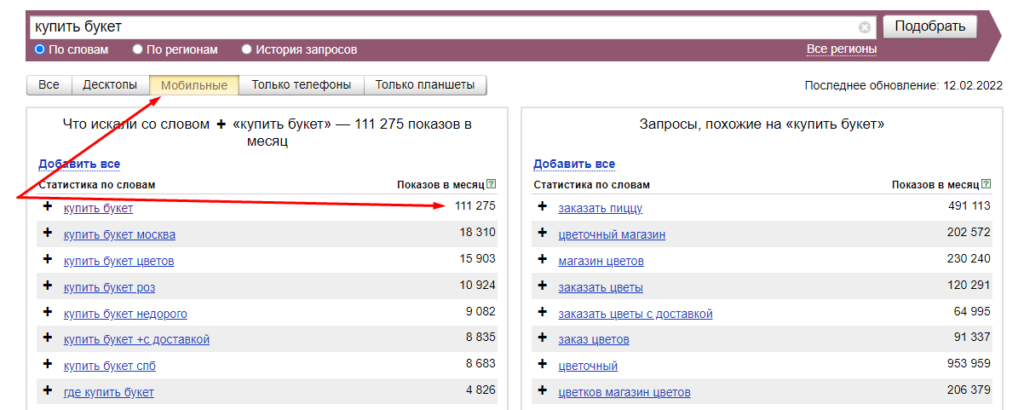
Устройства
В Яндекс.Вордстат можно посмотреть, с каких устройств чаще всего осуществляют поиск пользователи:
Эта информация поможет определиться с тем, насколько необходима мобильная версия сайта.
Под десктопами имеются в виду ноутбуки и персональные компьютеры.
Под мобильными — телефоны и планшеты.
В данном случае мы видим, что с мобильных устройств поиск осуществляется чаще:
Данные по регионам
Предположим, что мы собираемся открыть цветочный магазин, который осуществляет доставку только в Тюмени. Соответственно нас интересует спрос в пределах этого города, а не по всему миру. Под строкой ввода выбираем регион:
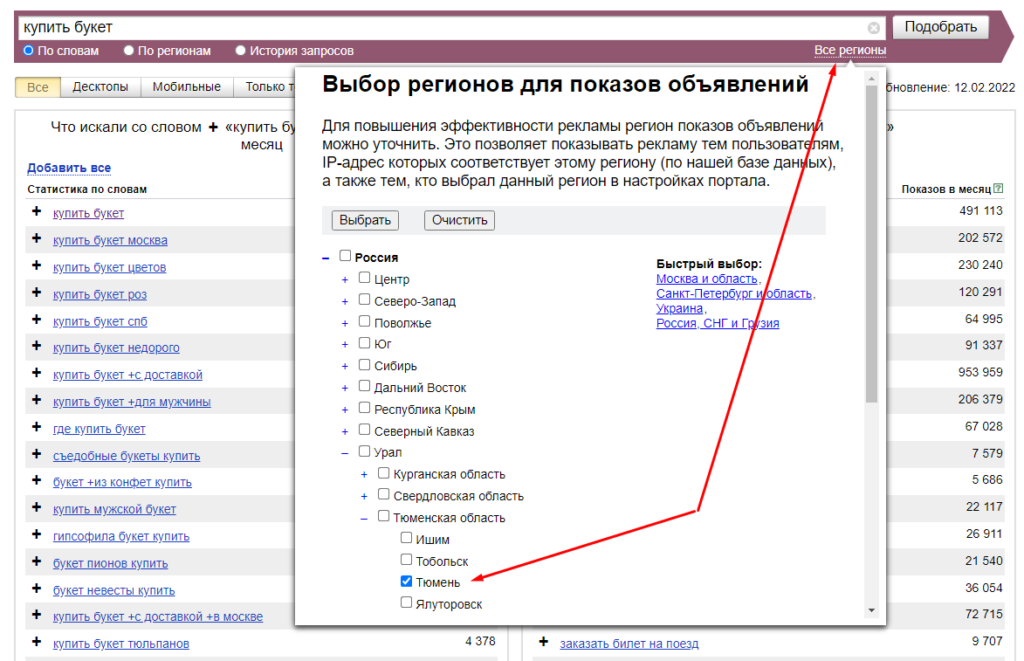
К сожалению, здесь нет строки для поиска региона, поэтому будет возможность подтянуть немного знания по географии. Ну или просто загуглить, в каком регионе находится нужный город.
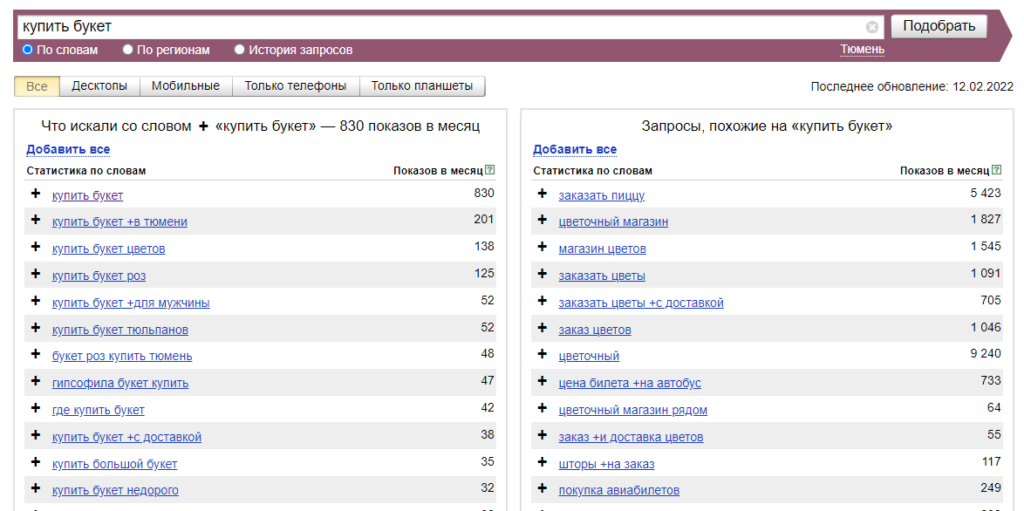
После уточнения региона значения выглядят менее радужно — вместо 149 089, теперь 830 показов в месяц. При этом держим в голове, что 830 показов включают в себя и другие запросы.
Вкладка «по регионам»
Посмотреть статистику популярности запроса в других регионах можно во вкладке (радиокнопке) «По регионам»:
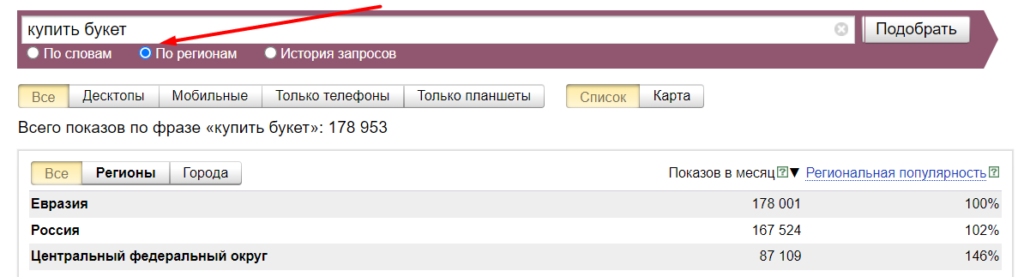

Здесь есть показатель «региональная популярность». Вот определение Яндекса:
«Региональная популярность» — это доля, которую занимает регион в показах по данному слову, деленная на долю всех показов результатов поиска, приходящихся на этот регион. Популярность слова/словосочетания, равная 100%, означает, что данное слово в данном регионе ничем не выделено. Если популярность более 100%, это означает, что в данном регионе существует повышенный интерес к этому слову, если меньше 100% — пониженный.»
Региональная популярность изучаемого запроса в Тюмени показывает пониженный спрос — 83% (важно — это значение относительно других запросов в данном регионе).
Помните первоначальные 149 089 показов по запросам? Обратите внимание, что в эти показы входят показы в том числе и по другим странам:

При переходе на вкладку «Карта» можно увидеть распределение запросов по странам. Для этого нужно навести курсор на интересующую область:
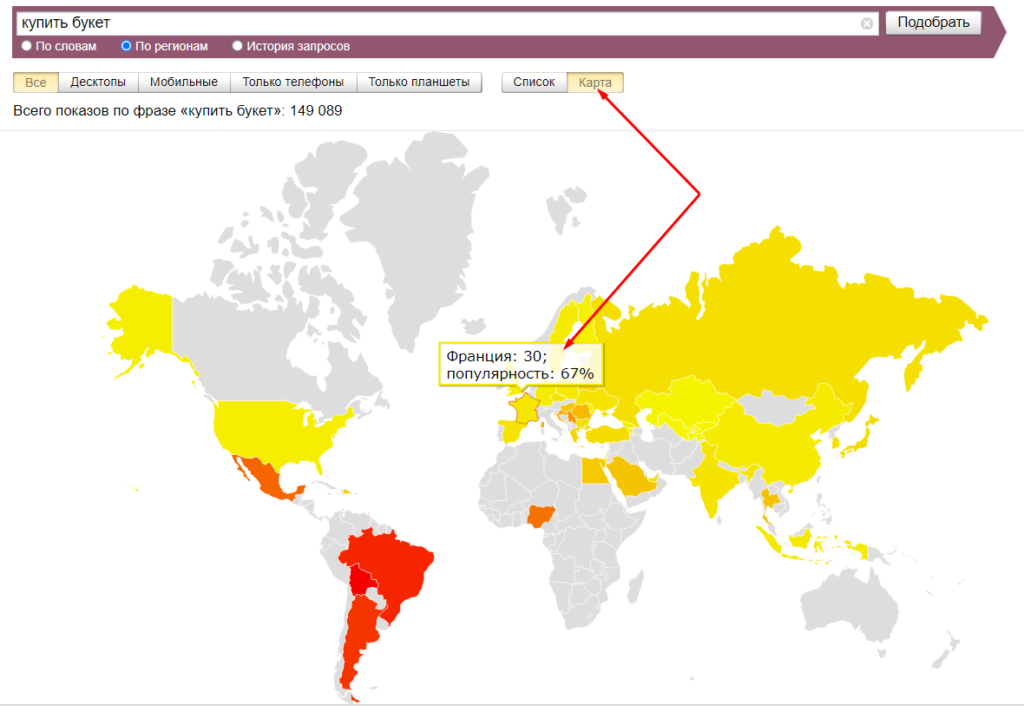
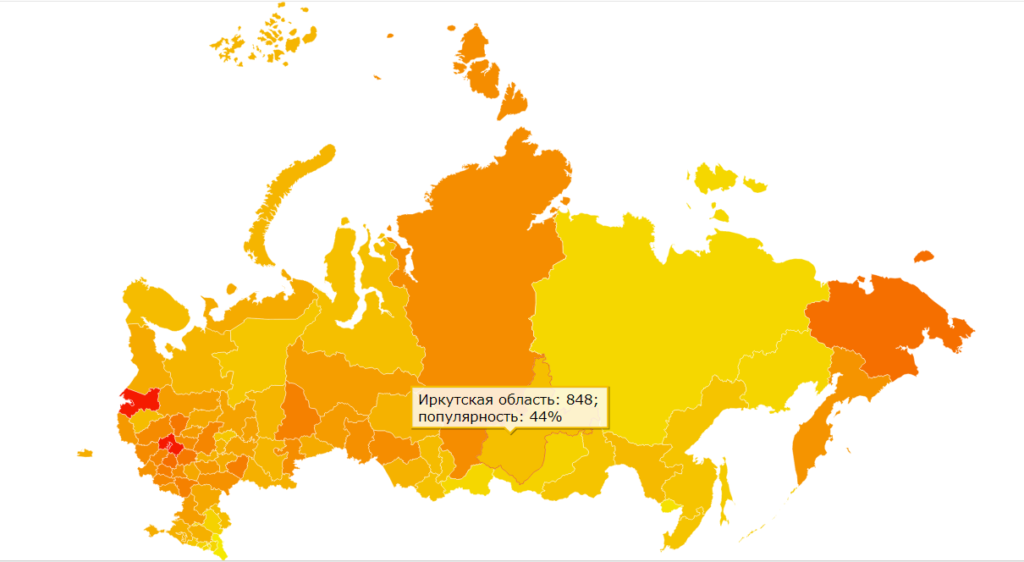
Некоторые регионы можно рассмотреть более детально. Например по России:
Всегда ли нужно учитывать регион?
При сборе семантического ядра лучше не указывать регион, либо выбирать более крупные города и районы, чтобы не упустить запросы, по которым есть мало данных для отдельных регионов. При этом не забывайте, что фактический спрос на эти запросы может быть другим, нежели общий.
Изучаем тренды
История запросов/тренды
Во вкладке (радиокнопке) «история запросов» собраны данные за два предыдущих года:
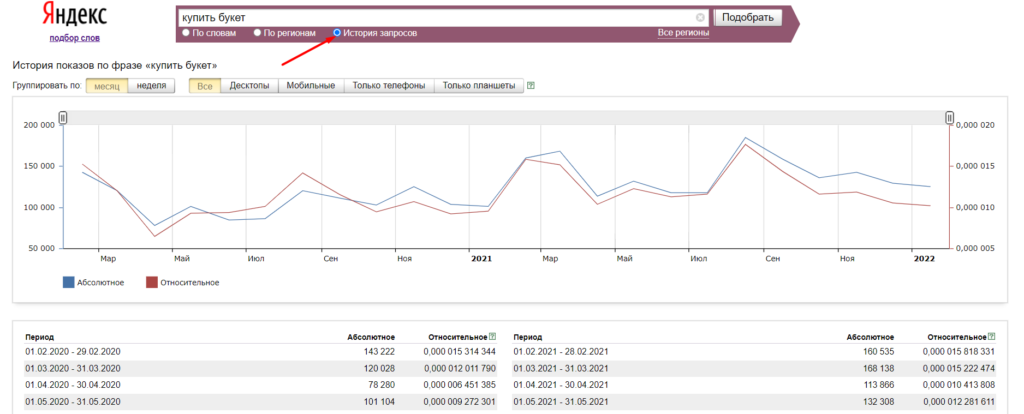
При изучении графика видно:
- повышенный спрос приходится на август, февраль, март;
- спрос растет;
- в апреле 2020 года спрос значительно ниже, чем в апреле 2021, вероятно в связи с началом пандемии.
Теперь перейдем к таблице. Для каждого месяца указаны абсолютные и относительные значения. Абсолютное — это фактическое значение количества сделанных запросов за месяц. Относительное — это отношение показов интересующего нас запроса к общему числу показов всех запросов в Яндексе, это показатель популярности запроса.
Важно: Этот отчет не поддерживает никаких операторов языка запросов. Пока что запомните эту информацию, подробнее про операторы поговорим чуть ниже.
Графики абсолютных и относительных значений должны повторять друг друга. Если же есть резкие расхождения, это может говорить о накрутках запроса.
При необходимости можно уточнить регион под строкой ввода:
Чтобы закрепить прочитанное, предлагаем посмотреть обзорное видео сервиса Wordstat от официального канала Яндекса:
Изучаем операторы
Для экономии времени и более точной статистики слов в Вордстате можно пользоваться специальными операторами, которые помогают быстро отфильтровать необходимый список ключевых фраз.
Оператор «!» (восклицательный знак) фиксирует падеж, род и число слова, то есть при подборе фраз форма слова не меняется.
Например, нужно подобрать фразы о продаже цветов в горшках. Запрос без оператора даст результат, где будет много неподходящих запросов. Например, о покупке горшка для цветов.
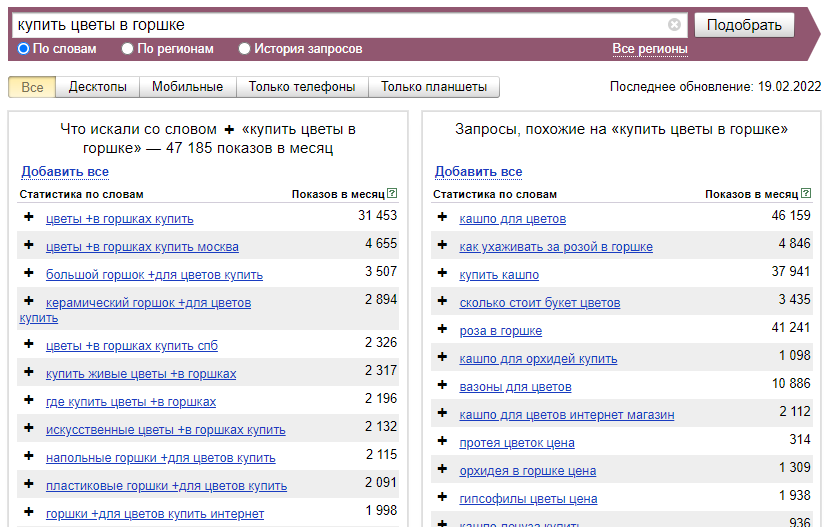
На скриншоте видно, что, при фиксации слова !горшке, в выдаче отсутствуют формы слова: горшок, горшки и прочие:
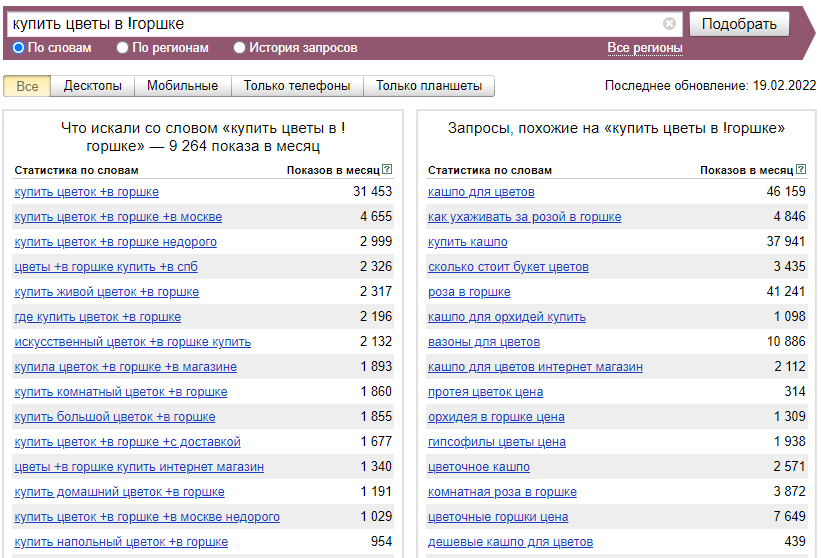
Оператор «” “» (кавычки) фиксирует количество слов, расположенных между кавычками, но не фиксирует форму слов и их порядок. Фразы, которые содержат меньшее или большее количество слов, показываться не будут.
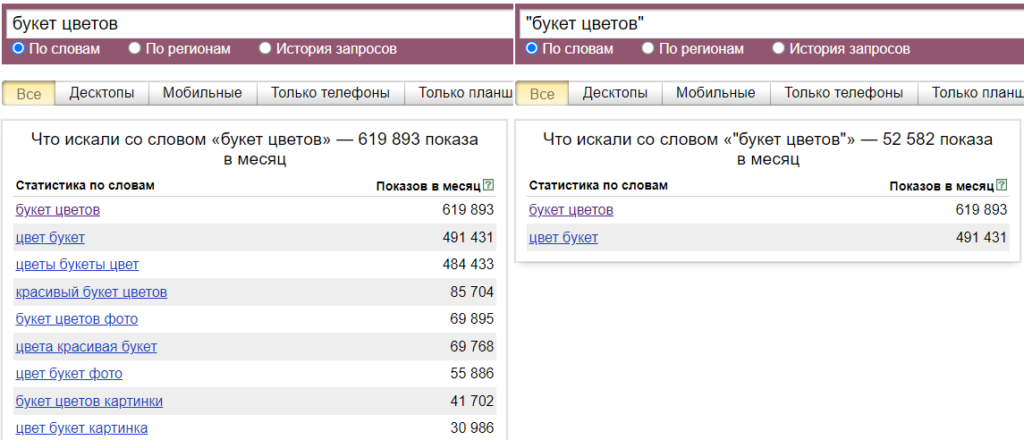
У этого оператора есть дополнительный функционал. Если внутри кавычек продублировать какое-то слово, то в результатах мы увидим фразы нужной нам длины, которая будет соответствовать количеству слов внутри кавычек, и с вхождением перечисленных слов.
Оператор «+» (плюс) закрепляет служебные части речи — частицы, союзы, предлоги — и местоимения, которые по умолчанию Вордстат не учитывает.
Допустим, нужно найти запросы для букетов, которые продаются с водой, чтобы цветы не вяли. Такая подборка по запросу «Купить букет в воде» получается без использования оператора:
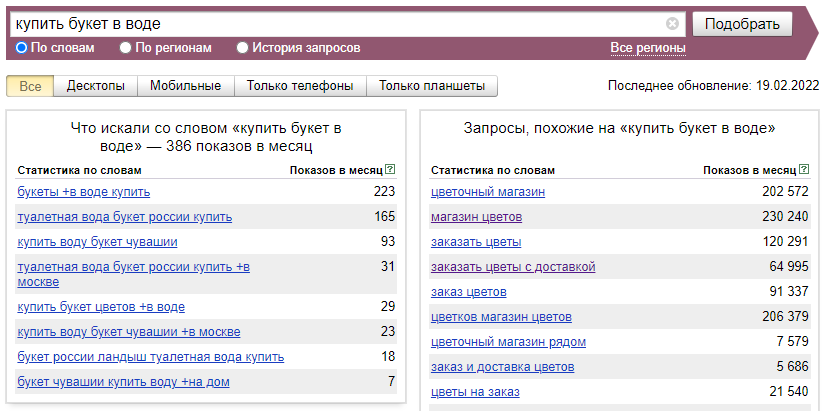
Мы видим нецелевые фразы: туалетная вода букет россии купить, купить воду букет чувашии, туалетная вода букет россии купить в москве и другое.
А закрепление предлога «в» и формы слова «!воде» позволяет оставить в результатах только подходящие фразы.
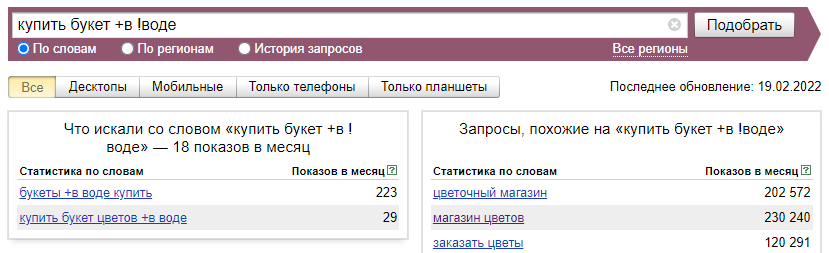
Оператор «[ ]» (квадратные скобки) фиксирует порядок слов, а также учитываются стоп-слова и словоформы. Прежде всего, это удобно использовать в логистических тематиках.
Допустим, нам интересна оптовая продажа цветов, поэтому мы решили найти запросы про перевозку грузов из Санкт-Петербурга в Москву. В этом случае воспользуемся оператором, который уберет из результатов направление Москва – Санкт-Петербург.
![Оператор «[ ]» (квадратные скобки)](https://blog.webit.ru/wp-content/uploads/2022/04/image27-1024x327.png)
Оператор «|» (или) — логическая функция ИЛИ, которая позволяет искать фразы с синонимами, причем этот оператор используется вместе с оператором группировки — «()» (круглые скобки).
Эта группа операторов полезна, когда продвигаемый товар можно назвать по-разному, и нас интересуют фразы со всеми его синонимами. Например, цветы и букет:
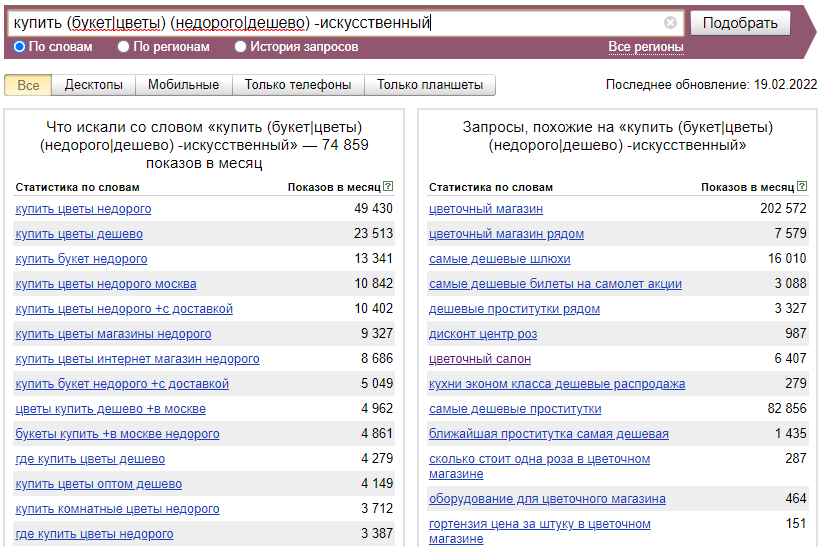
Оператор «-» (минус) позволяет убрать фразы, которые содержат неподходящие слова. Из предыдущей подборки уберем фразы с искусственными цветами, которые мы не продаем:
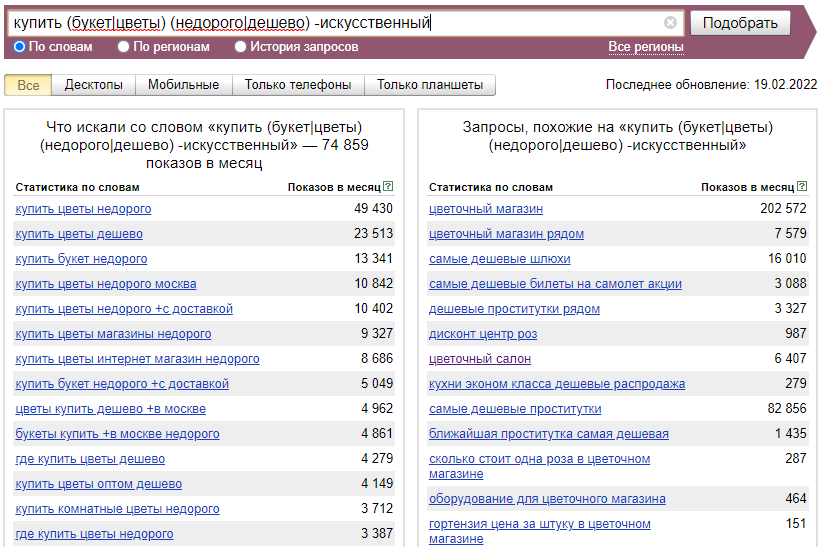
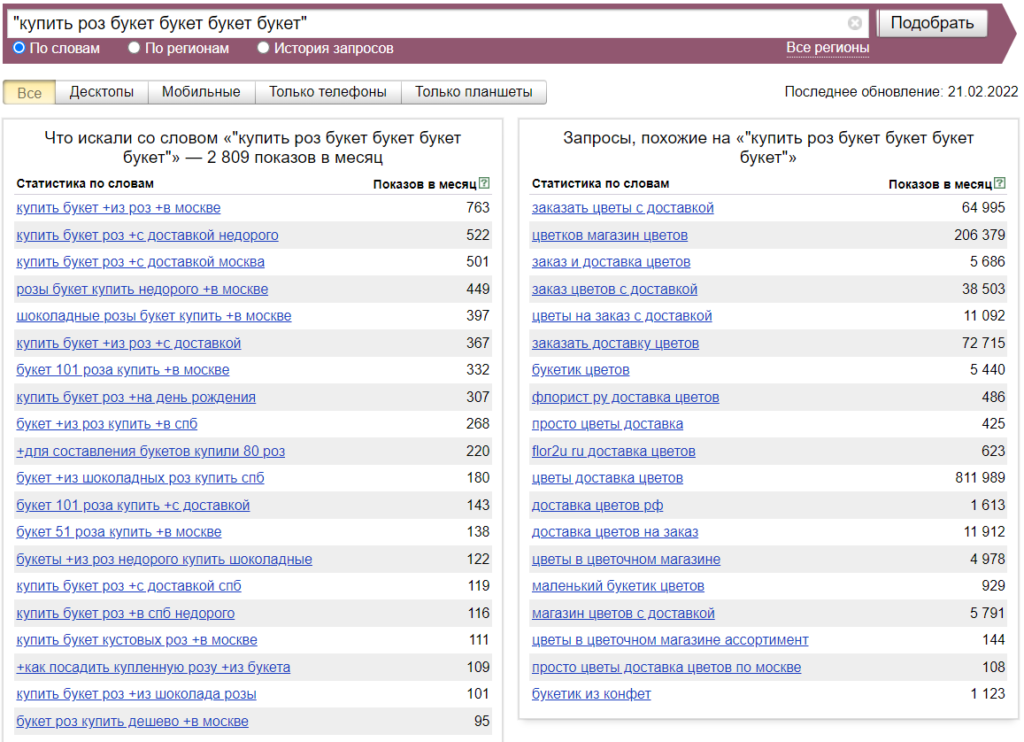
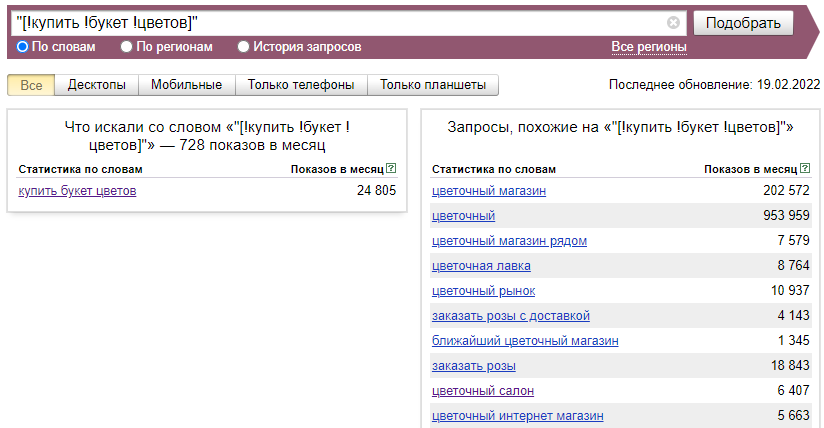
Все перечисленные операторы можно комбинировать между собой. Так, если нам необходимо узнать точную частотность запроса, то мы используем следующую комбинацию операторов: «[!купить !букет !цветов]».
В этом случае точная частотность данного запроса по всем регионам — 728 показов в месяц, а не 24 805. Потому что, как мы разобрали выше, число показов, которое указано в левой колонке, включает не только статистику конкретной фразы, но и сумму вложенных запросов.
Как правильно собрать семантическое ядро в Вордстат?
Здесь мы рассмотрим вариант ручного сбора семантического ядра с помощью Яндекс.Вордстат. Этот метод бесплатный, но достаточно трудоемкий и времязатратный. Он подходит либо для небольших сайтов, либо для ознакомления с процессом сбора семантики. Для постоянной работы лучше использовать специальные инструменты, такие как Key Collector и A-Parser. Данные программы являются платными, но при большом объеме работы они очень удобны и экономят много времени.
Для примера возьмем направление — сайт небольшого цветочного магазина, который осуществляет доставку в пределах Москвы и продает исключительно один вид цветов — пионы.
Начнем со слова «букет», выбираем регион Москва без Зеленограда, Троицка и Щербинки.
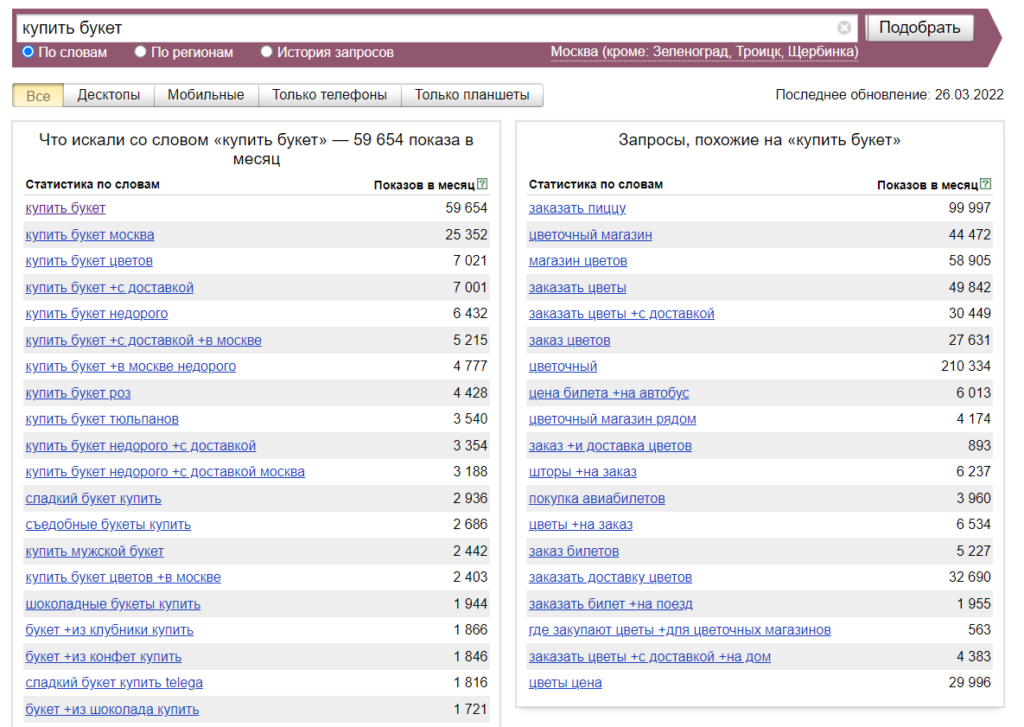
Выделяем и копируем в свою таблицу фразы и частотность из левой колонки (Ctrl+C → Ctrl+V). Переходим по страницам и добавляем запросы в таблицу:
Скачать шаблон таблицы можно по ссылке.
В конце статьи расскажем про бесплатный инструмент Yandex Wordstat Assistant, который ускорит этот процесс в разы.
Для примера скопируем первые 150 запросов. Всего Яндекс.Вордстат показывает по 50 запросов на каждой странице. Максимальное число страниц для этой фразы — 10, на последней странице 32 запроса. Значит, всего можно собрать 482 фразы.
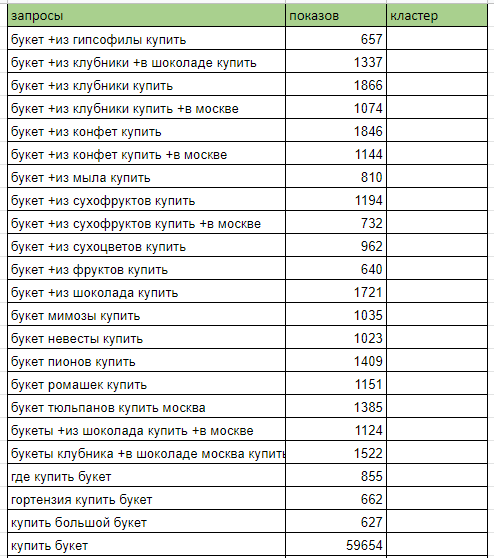
Теперь займемся группировкой запросов. Посмотрим, какие есть запросы:
- указание получателя (для мужчины, для женщины);
- указание повода (с днем рождения, невеста);
- мусорные запросы:
- вид цветов отличный от пионов (мимозы, ромашки);
- букеты без использования цветов (из конфет, из фруктов);
- «букет цветов фото», «букеты картинки» — запросы не являются коммерческими и не относятся к продаже букетов. Также сюда нужно отнести запросы с упоминанием конкурентов, запросы с опечатками, информационные запросы, если на сайте нет информационного блога. Если он есть и вы собираетесь его продвигать, то добавьте информационные запросы в отдельные кластеры.
Удаляем мусорные запросы, а оставшиеся распределяем по группам. В итоге получается такая картина:
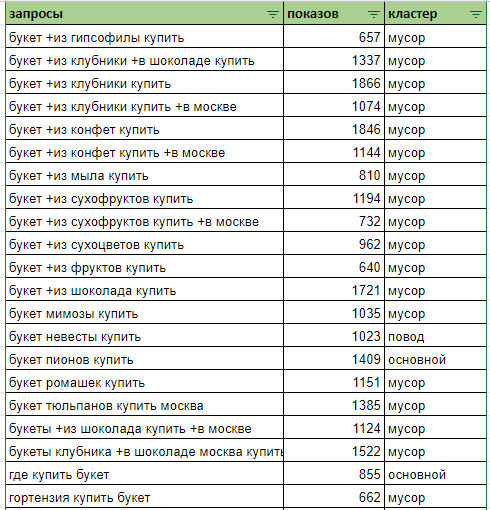
Мусорных — 109 запросов, всего кластеров — 5.
Такой результат получился из 150 запросов. Для получения наиболее полного семантического ядра нужно проанализировать больше слов. Для расширения списка можно собрать запросы по другим фразам, например «букет пионов»:
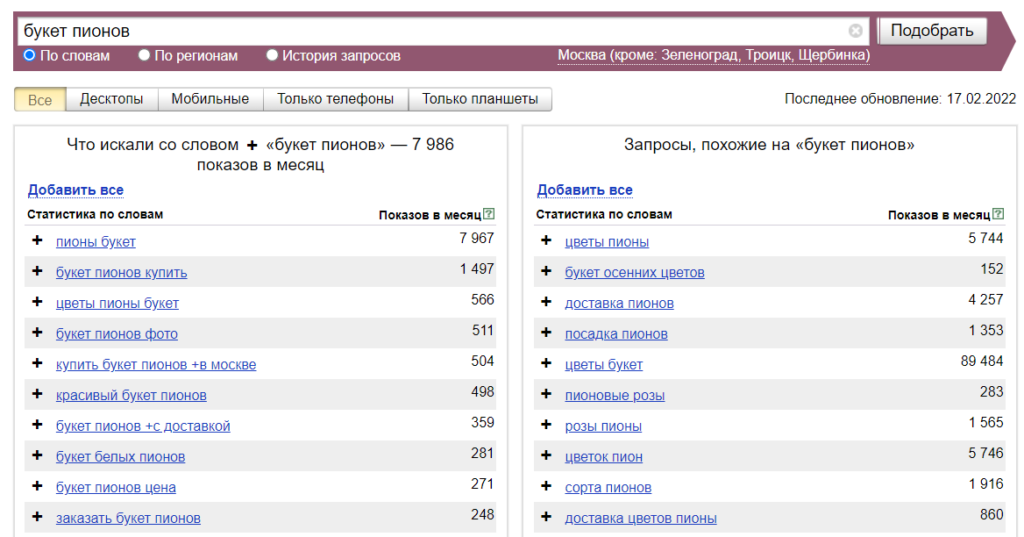
Коммерческие и информационные запросы
Для правильной группировки запросов необходимо понимать, какие типы запросов существуют. Рассмотрим запросы по типу интента (т.е. намерения):
- информационные,
- коммерческие,
- навигационные.
Коммерческие запросы отражают намерение пользователя приобрести товар или услугу, могут содержать слова «купить», «заказать», «цена». Такие запросы обычно используют при продвижении карточек товаров, листингов товаров, страниц с услугами.
Информационные запросы задают в поиск в образовательных или ознакомительных целях для получения дополнительной информации по интересующему вопросу.
Часто такие запросы могут содержать вопросительные слова: «как», «какой», «почему», «что такое» или не содержать однозначной потребности покупки товара или услуги. Например, «какие букеты сейчас в тренде», «ранункулюс это», «роза», «как составить букет».
Такие запросы обычно используют при продвижении раздела блога на коммерческих сайтах или для информационных порталов.
Навигационные запросы содержат в себе название сайта, домена или бренда. Такие запросы пользователи вводят с целью найти определенный сайт. Например, «официальный сайт мосцветторг», «ozon».
Геозависимые и геонезависимые запросы
Геонезависимые запросы – запросы, по которым поисковая выдача не отличается в разных регионах. Как правило, это информационные запросы. Например, «значение цветка лилия».
Геозависимые запросы – запросы, по которым поисковая выдача отличается в разных регионах. Например, посмотрим как изменится выдача запроса «купить букет» для региона Москва и Тюмень:
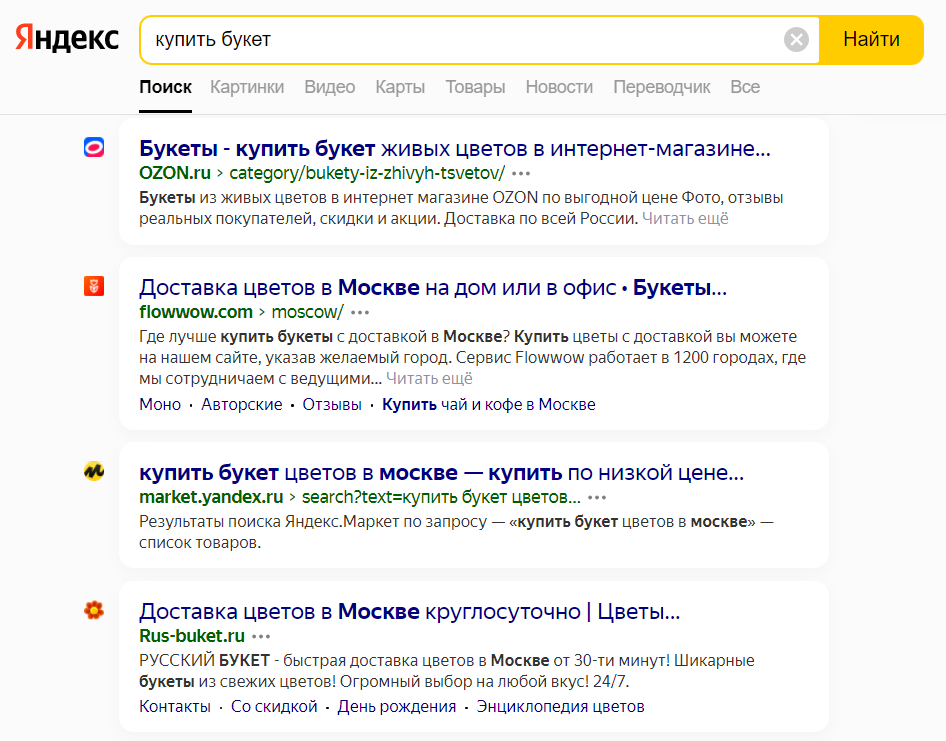
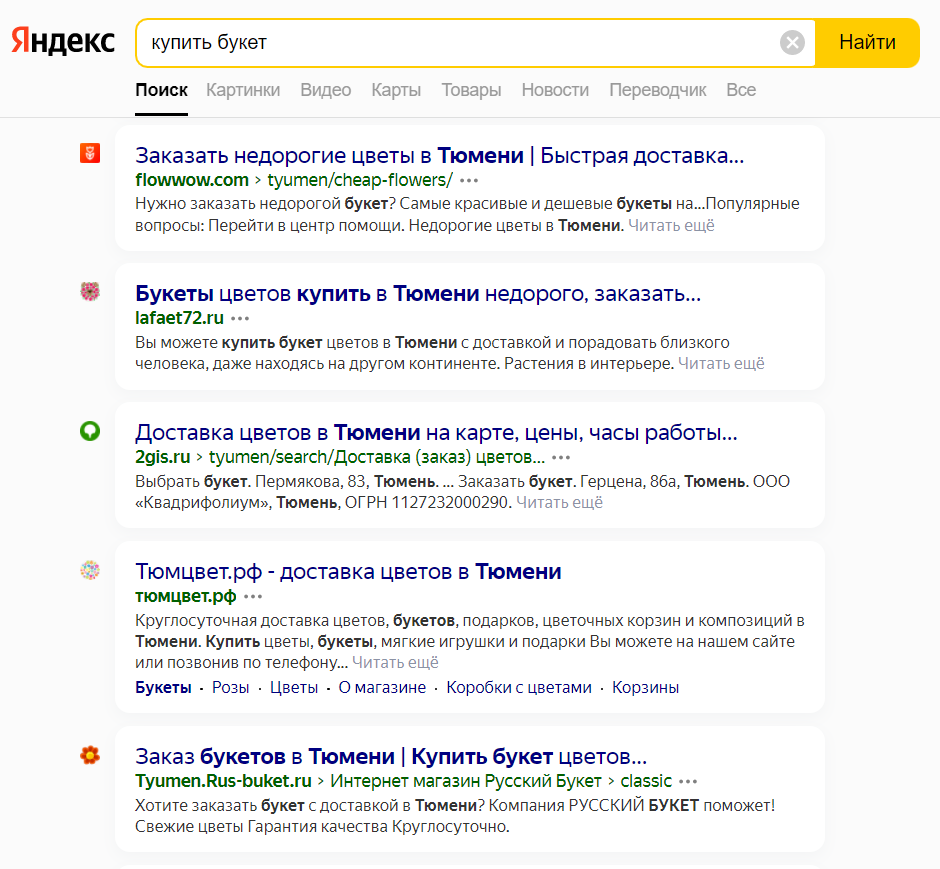
Не смотря на то, что в запросе не указан регион, в поисковой выдаче мы видим разные ресурсы, ориентированные на тот регион, в котором осуществлялся поиск.
Почему так важно понимать отличие типов запросов?
Не стоит смешивать информационные и коммерческие запросы, при составлении семантического ядра. Поисковые системы анализируют URL, контент, ссылки страниц и определяют какие сайты и страницы на сайте точнее всего отражают запрос пользователя.
То есть, если вы продаете одежду, но на коммерческих страницах присутствует много информации, которая отвечает на множество информационных запросов, то поисковая система будет реже показывать эти страницы для пользователей, которые хотят купить и чаще для тех, которые хотят получить ответы на свои вопросы.
Работа с API Wordstat
Можно работать с Wordstat напрямую, копируя нужные слова, а можно опосредованно, используя сторонние сервисы и плагины, о которых мы поговорим в конце статьи, но есть и третий вариант — автоматизировать процесс сбора данных с помощью создания собственного приложения, которое будет запускать парсинг запросов в Yandex Wordstat.
Это возможно, потому что Яндекс предоставляет бесплатные доступы ко многим своим инструментам через API (application programming interface) — программный интерфейс приложения. В том числе API есть у Wordstat.
Собственные приложения или сторонние сервисы избавляют специалистов от рутинных действий, ускоряют рабочие процессы и дают возможность тратить время на более творческие задачи, что повышает вовлеченность сотрудников и качество работы.

Чтобы начать разработку приложения, нужно выполнить следующие шаги по инструкции:
- Зарегистрировать приложение на OAuth-сервере Яндекса и отправить заявку на доступ.
- Создать тестового пользователя и данные для него.
- Зарегистрировать аккаунт тестового пользователя в Яндексе.
- Создать рекламную кампанию в Яндекс.Директе от имени тестового пользователя.
- В разделе API Яндекс.Директа нажать ссылку «Получить доступ к API» и принять пользовательское соглашение.
- Включить Песочницу — среду для отладки, где можно управлять созданными кампаниями без реальных показов и внесения средств.
- От имени тестового пользователя получить отладочный токен.
Каждый из этих пунктов подробно рассмотрен в обучающем руководстве Яндекса. Также за дополнительной помощью всегда можно обратиться в техподдержку API Директа.
Дополнительное ПО для работы с Яндекс.Вордстат
Выше мы рассмотрели, как можно создать собственный скрипт или приложение для сбора ключевых фраз, но есть и более простое решение — использование готовых бесплатных расширений. Самые популярные из них — Yandex.Wordstat Helper и Yandex Wordstat Assistant. Давайте узнаем, как с ними работать.
Yandex.Wordstat Helper
Для начала работы с расширением его нужно скачать в магазине Google Chrome — ссылка. После установки приложения его виджет появится на странице Яндекс Вордстата.
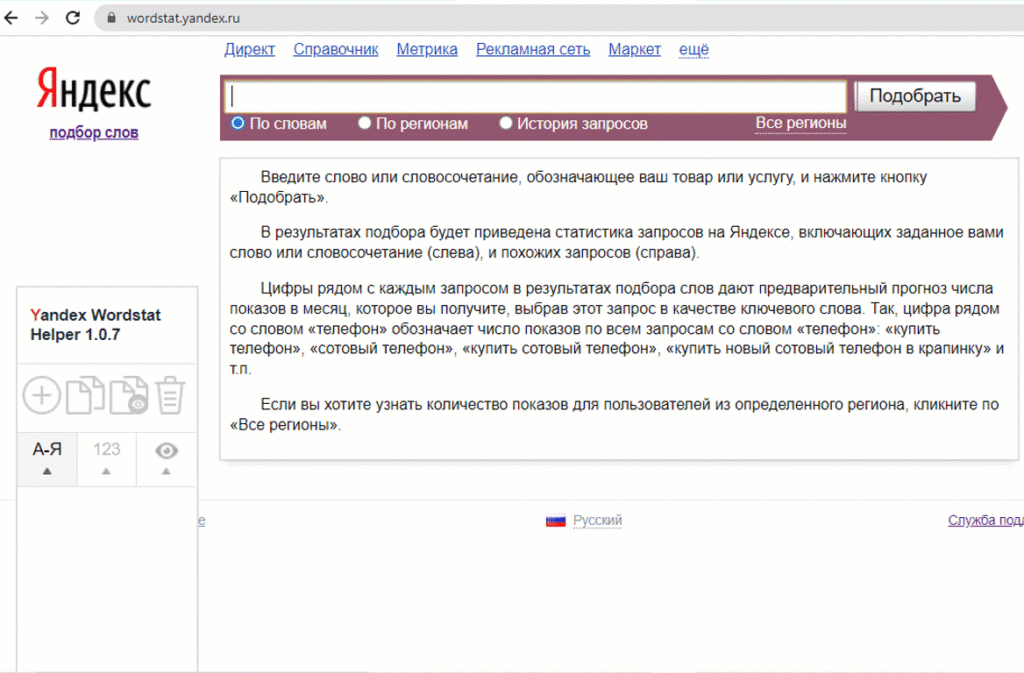
Доступные возможности расширения:
- сортировка по порядку добавления фраз, по частотности или по алфавиту в порядке убывания и возрастания,
- проверка на дубли,
- копирование в буфер обмена в один клик с частотностью и без,
- счетчик количества добавленных слов и частотности,
- массовое удаление слов,
- добавление своей ключевой фразы.
Yandex Wordstat Assistant
Установить расширение можно по ссылке.
Приложение интерфейсом и функционалом похоже на предыдущее. Принцип тот же — видим целевую фразу и нажимаем «+», чтобы добавить ее в наш список. Этот список фраз с частотностью затем можно скопировать и вставить в табличный редактор.
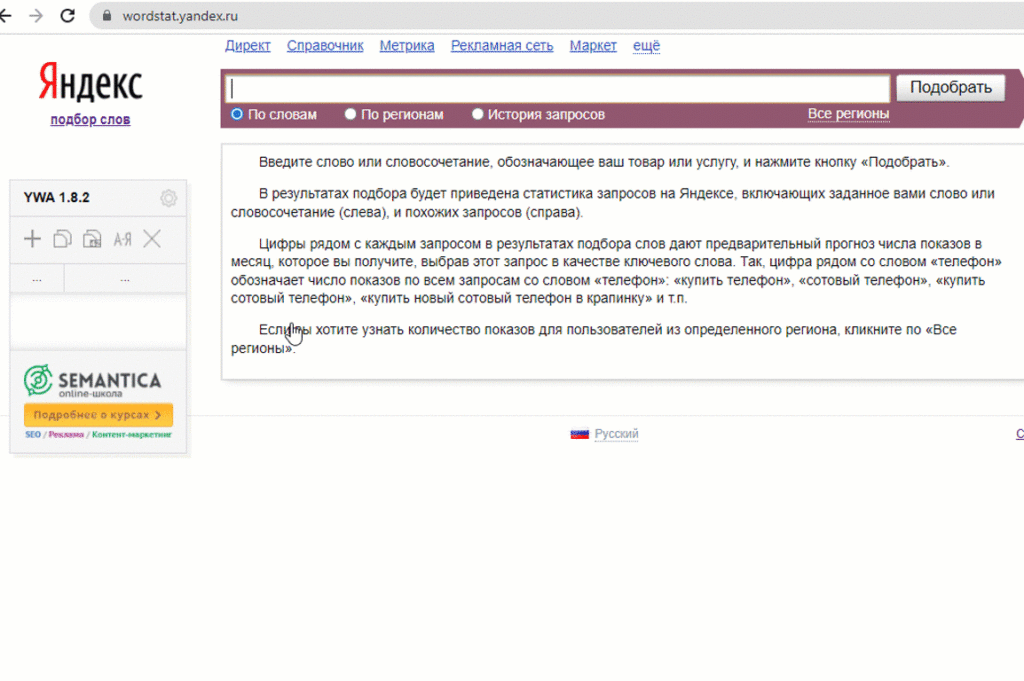
Возможности расширения:
- сортировка по порядку добавления фраз, по частотности или по алфавиту в порядке убывания и возрастания;
- проверка на дублирование фраз;
- ручные списки можно добавлять группой в уже сформированный список;
- автосохранение фраз при закрытии вкладки;
- поддержка нескольких вкладок при работе из одного браузера;
- массовое удаление слов.
Статью подготовили Светлана Кабалина медиапланер Webit и Александра Иванова SEO-специалист Webit.
