Содержание
Google Search Console – прекрасный инструмент для аналитики данных по проекту в поиске. Но есть одна особенность, которая сильно ограничивает в возможностях при работе с инструментом — просмотреть статистику можно только основываясь на 1000 самых популярных запросов или страниц. Для получения более детальной информации мы рекомендуем использовать GSC в связке с регулярными выражениями. С помощью регулярных выражений можно фильтровать большое количество данных и выбирать только те, которые соответствуют шаблону.
Зачем и для чего?
- Возможность фильтровать запросы по условиям;
- Возможность смотреть статистику по списку урлов с определенным критерием.
Какие задачи позволит решить?
- Выявление проблем с индексацией;
- Поиск возможных точек роста при анализе выборки запросов;
- Оценка CTR по набору запросов или урлов.
Как с этим работать
С регулярными выражениями можно работать в 3 отчетах в разделе “Эффективность”:
- Результаты поиска — здесь показываются данные непосредственно из поиска Google;
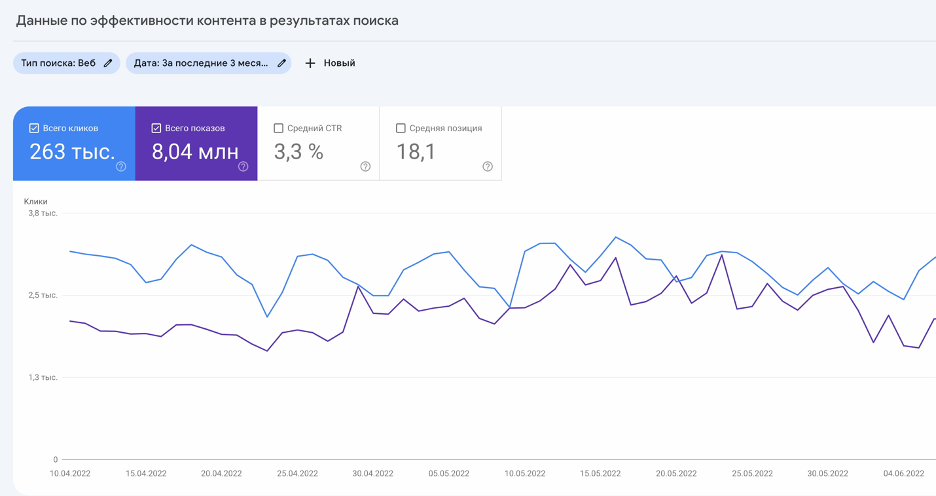
- Google Discover (Рекомендации) – данные из приложения Google и браузера в телефоне;
- Новости — статистика по показам сайта в мобильном приложении Google и с сайта news.google.com.
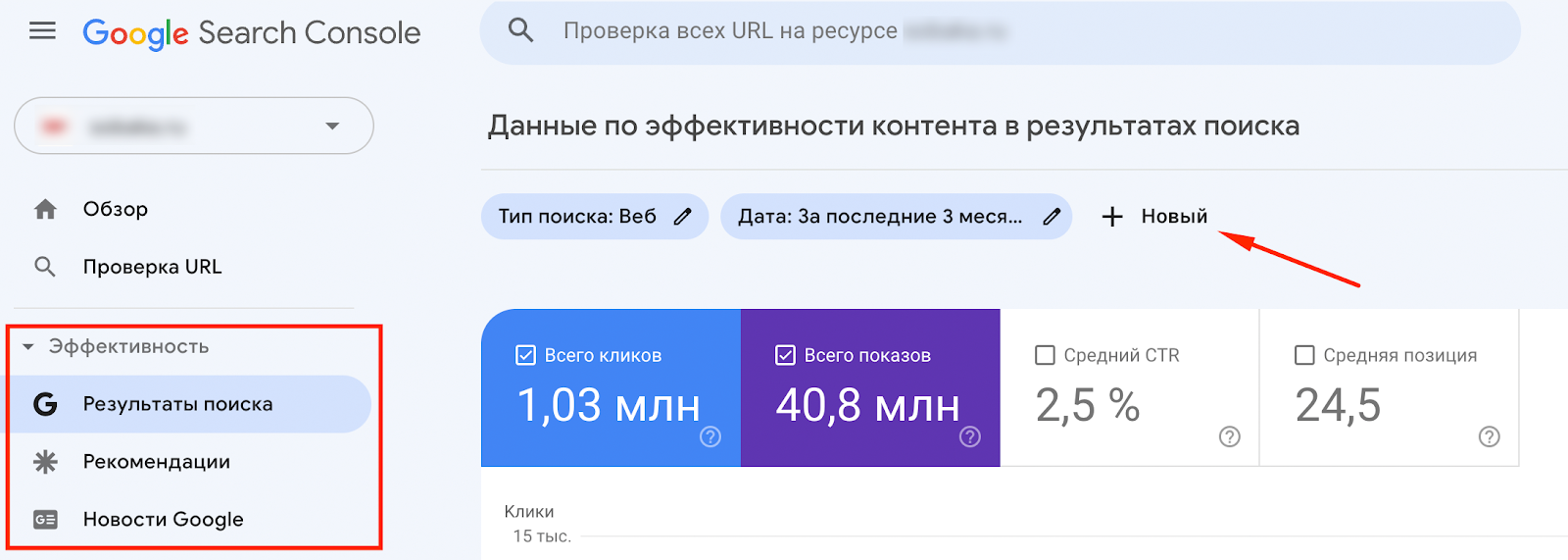
Интерфейс
Квадратом обозначены разделы, где можно работать с “регулярками”, стрелкой — поле, куда вбиваются регулярные выражения:
Ограничения
- Нельзя использовать отрицание, так как в интерфейсе возможность получить результаты, НЕ соответствующие регулярному выражению, выведена отдельно:

Это накладывает свои ограничения, потому что невозможно использовать связки
(утверждение 1) И (отрицание утверждения 2);
- Длина регулярного выражения не должна превышать 4096 символов.
Примеры использования
Поиск коммерческих запросов
| – ИЛИ — используется если нужно найти запросы, которые соответствуют одному или другому критерию. Например, можно ввести конструкцию купить|цена и в результате получить запросы как со словом “купить”, так и со словом “цена”:
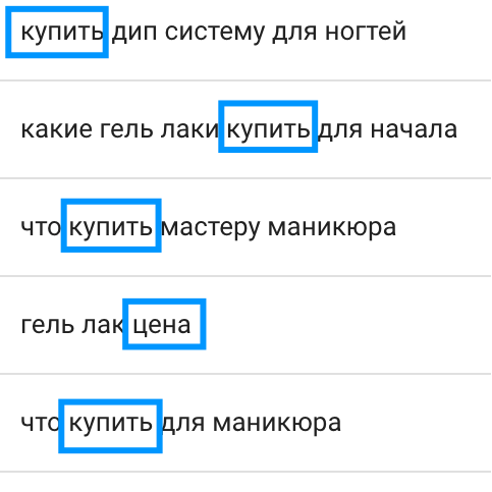
Исключение нерелевантных запросов
[x-z] — группа символов. Используется, когда нужно указать группу символов. Например, необходимо исключить запросы, содержащие года 21 века. Можно использовать оператор ИЛИ и перечислить через знак | все года, начиная от 2000 до 2022, а можно использовать менее громоздкую конструкцию: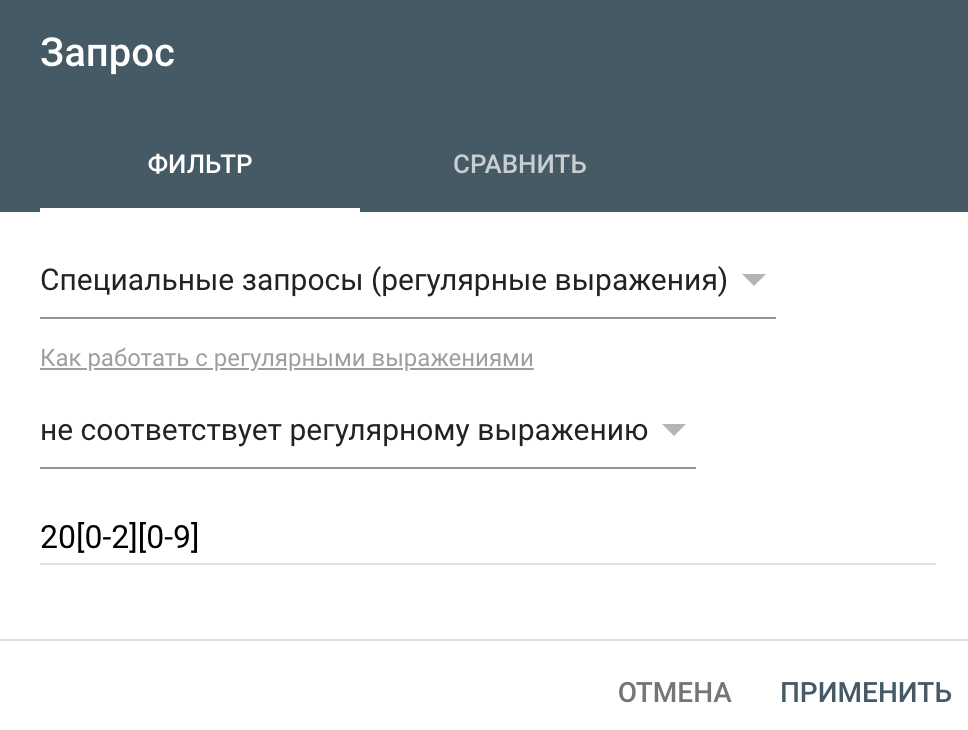
где в первых квадратных скобках мы указываем диапазон цифр от 0 до 2 включительно, а во втором — диапазон от 0 до 9.
Исключение информационных запросов
Пример регулярки для интернет-магазина строительного оборудования. Список стоп-слов вносится на основе анализа популярных ключевых слов проекта.
чем|как|что|можно|или|когда|отзывы|своими|руками|студент|характеристики|как|габрадиабас|полезные|время|обслуживание|страна|инструкция|русском|производитель|или|и|минусы|б/у|чего|устройство|это|фото

Просмотр статистики по определенной группе страниц
Представим, что нам нужно посмотреть статистику по всем товарам в категории “Тюльпаны”. Мы бы могли использовать фильтр “URL, содержащие”:

и в условие добавить алиас категории “tyulpany”, но проблема в том, что в разделе “Тюльпаны” у нас есть дочерние категории, например, “Тюльпаны многоцветковые”, которые соответствуют условию, но не нужны нам для статистики. Для этого мы ищем условие, под которое подходят все товары, но не подходят категории. В нашем проекте товар имеет в адресе id, состоящий из набора цифр количеством от 5 до 7. Пример: https://site.ru/catalog/tyulpany/mnogotsvetkovye/48345/. У нас получается следующая конструкция:
tyulpany.*\d{5,7}
Где tyulpany – алиас нужной категории; .* – любой набор символов, потому что товар может лежать в любой дочерней категории; \d{5,7} – где с помощью \d – указываем, что нужно искать цифру, в фигурных скобках количество, т.е. от 5 до 7 цифр подряд включительно. Для проверки поможет сайт https://regex101.com/. Вводим свою регулярку в поле REGULAR EXPRESSION, примеры урлов для проверки в TESTING STRING и видим, что условию соответствует нужная нам строка:
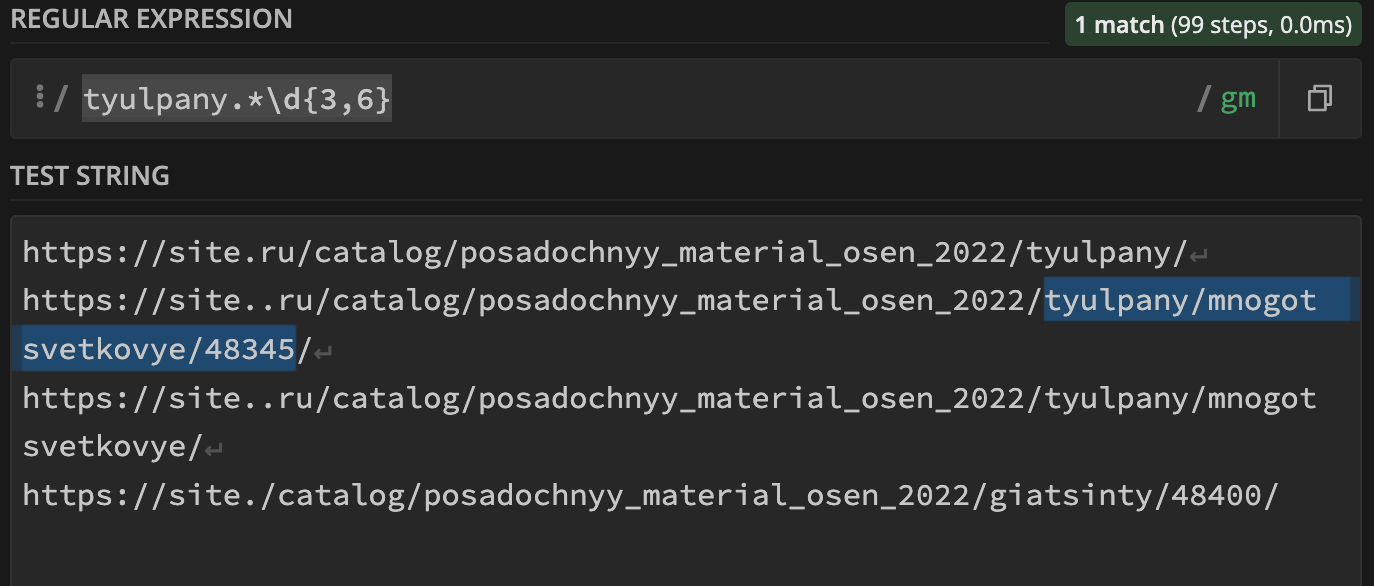
В блоке справа можно увидеть подробный разбор регулярного выражения и количество совпадений
Результат в GSC:
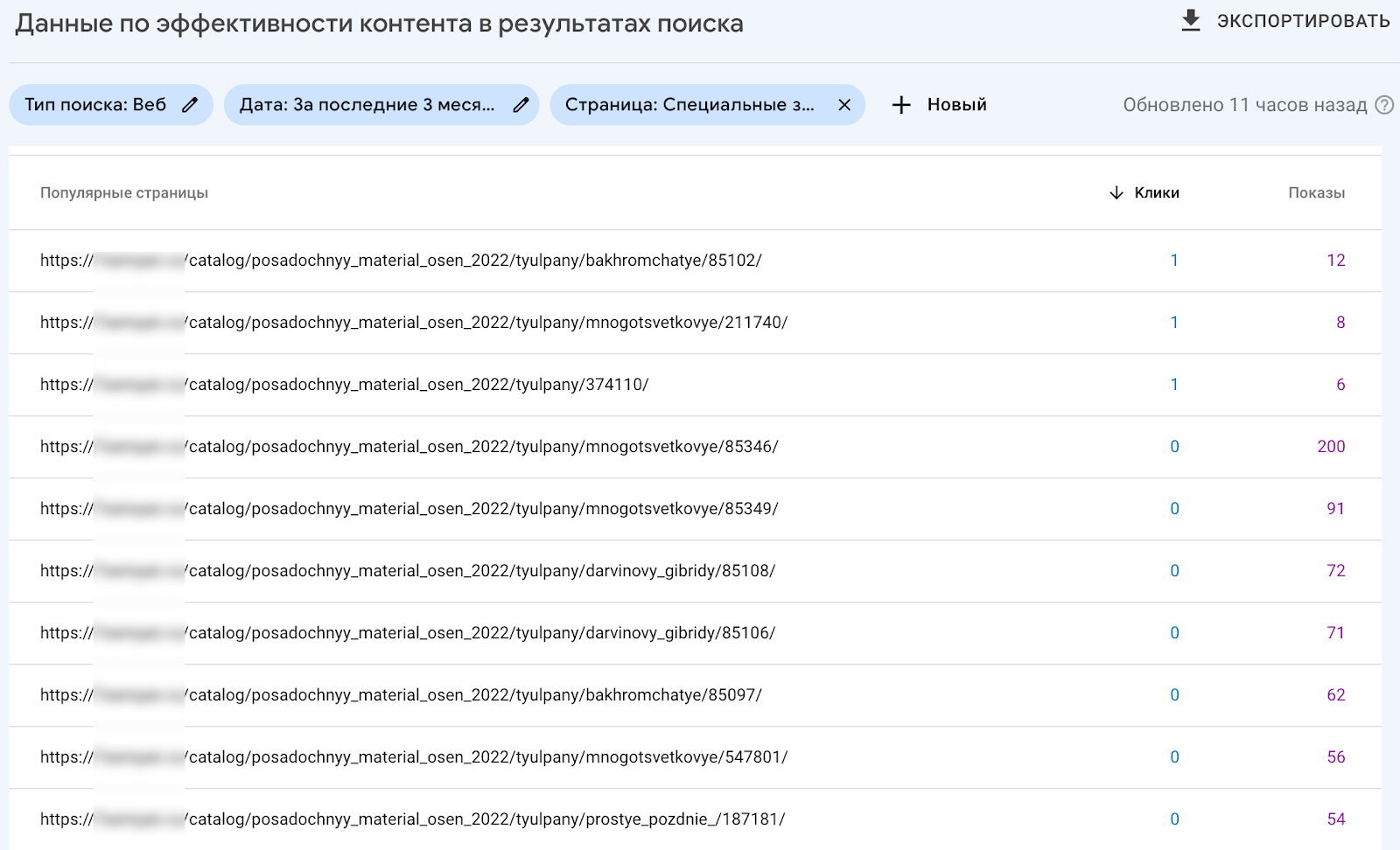
Если у вас есть определенный список урлов, по которому вы хотите посмотреть статистику, то можете воспользоваться таблицей. В указанные ячейки добавляется список адресов, а на выходе получаем готовое регулярное выражение для просмотра статистики по данной группе урлов.
Поиск страниц без слеша в конце урла
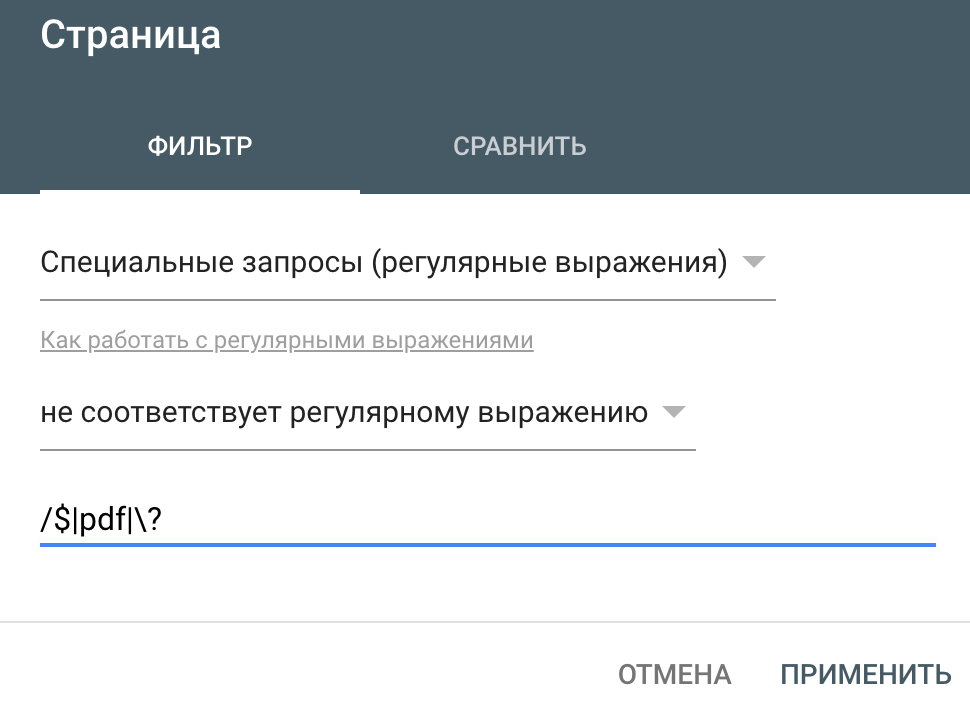
К примеру, у нас на сайте настроен редирект со страниц типа https://site.ru/catalog/nails на https://site.ru/catalog/nails/, но из-за особенностей CMS данная настройка может не работать для некоторых разделов. Также нам нужно исключить из результатов страницы, которые подходят под условие, но не нужны в статистике: файлы pdf (пример урла: https://site.ru/upload/filemanager/ukladkabrovei.pdf ) и страницы фильтрации (пример урла https://site.ru/shop/nails/gel-laki/page-16/?filter=1&sorting=). Итоговое выражение:
/$|pdf|\?
- /$, где $ – символ окончания строки, а / — символ, которым (не)должен оканчиваться адрес сайта;
- | – знак ИЛИ;
- pdf — исключаем файлы pdf;
- \? – исключаем страницы с фильтрацией, в адресе которых есть знак вопроса. Для того, чтобы сервис понимал, что это не часть синтаксиса регулярного выражения, а просто символ вопросительного знака, нам нужно экранировать символ, добавив перед ним обратный слеш \.
Добавляем эту конструкцию в фильтр с отрицанием (НЕ соответствует регулярному выражению)
Результат:

Исключение витальных запросов
К примеру, у магазина Имкосметик в статистике популярных запросов присутствует большое количество витальных запросов. К тому же, значительная часть пользователей пишет название по-своему: на латинице, кириллице и с ошибками. Пример запросов:
им косметика
инкосметик
im kosmetik
imcosmetic
имеосметик
ай эм косметик
Чтобы их исключить – используем такую конструкцию:
(^и[мн]|i[mn]|айм|айэм|ай\sэм)\s?([ек]осметик|[ck]osmeti[ck
- Скобки () используются для группировки условий;
- ^ — объявляем, что далее будет идти условие, которое должно находиться в начале строки;
- | — уже известный нам символ ИЛИ;
- скобки [] используются для перечисления возможных символов. Сервис выберет один символ, присутствующий в скобках. В нашем случае для условия и[мн] подойдет как им, так и ин;
Важно! в квадратных скобках перечисляемые буквы должны указываться в алфавитном порядке. Если мы будем использовать конструкцию и[нм], то в результатах у нас будут только строки с им
- \s — соответствует любому символу пробела;
- ? — означает, что предыдущее условие (\s) может встречаться 0 или 1 раз.
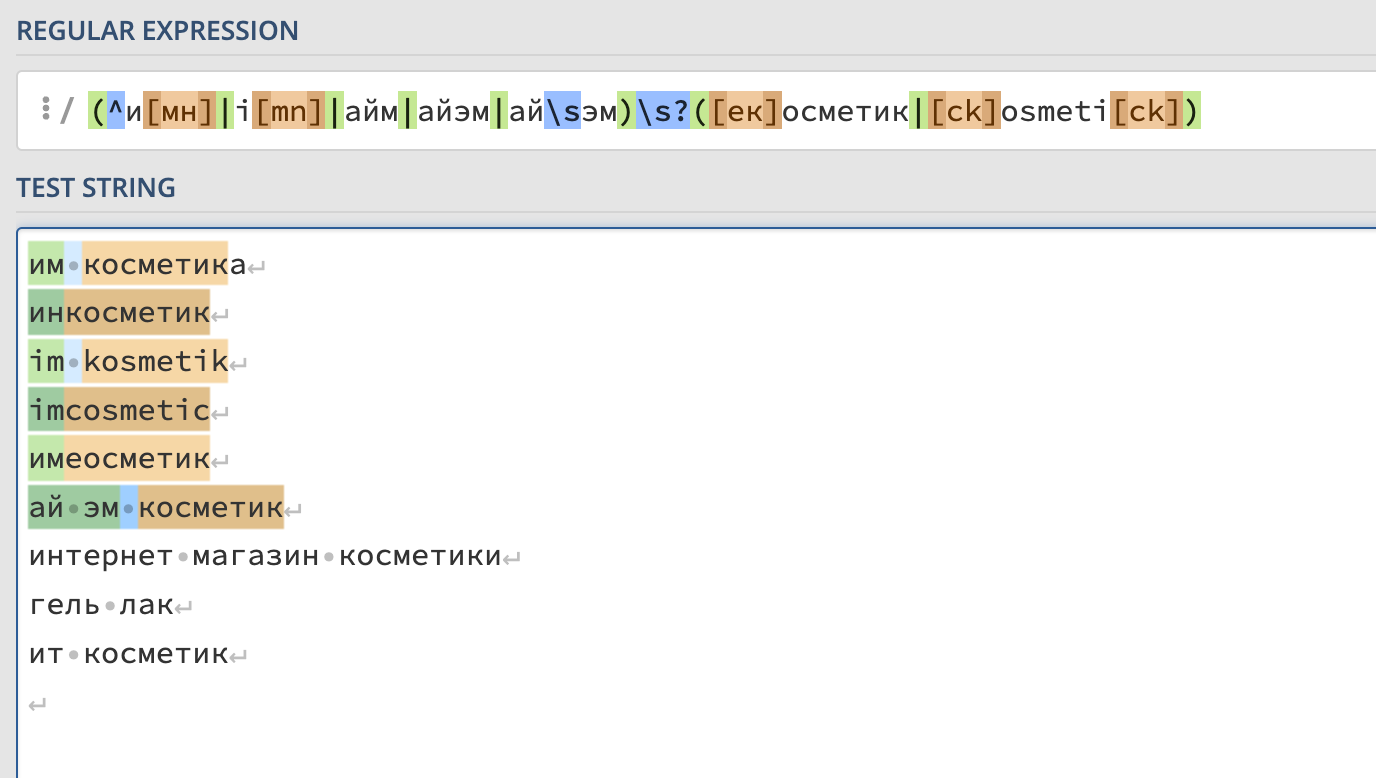
Для проверки можем использовать сервис https://regex101.com/:
Часто используемые конструкции
- Любое количество символов .*;
- Начало строки — ^. Пример ^спб; Результат:
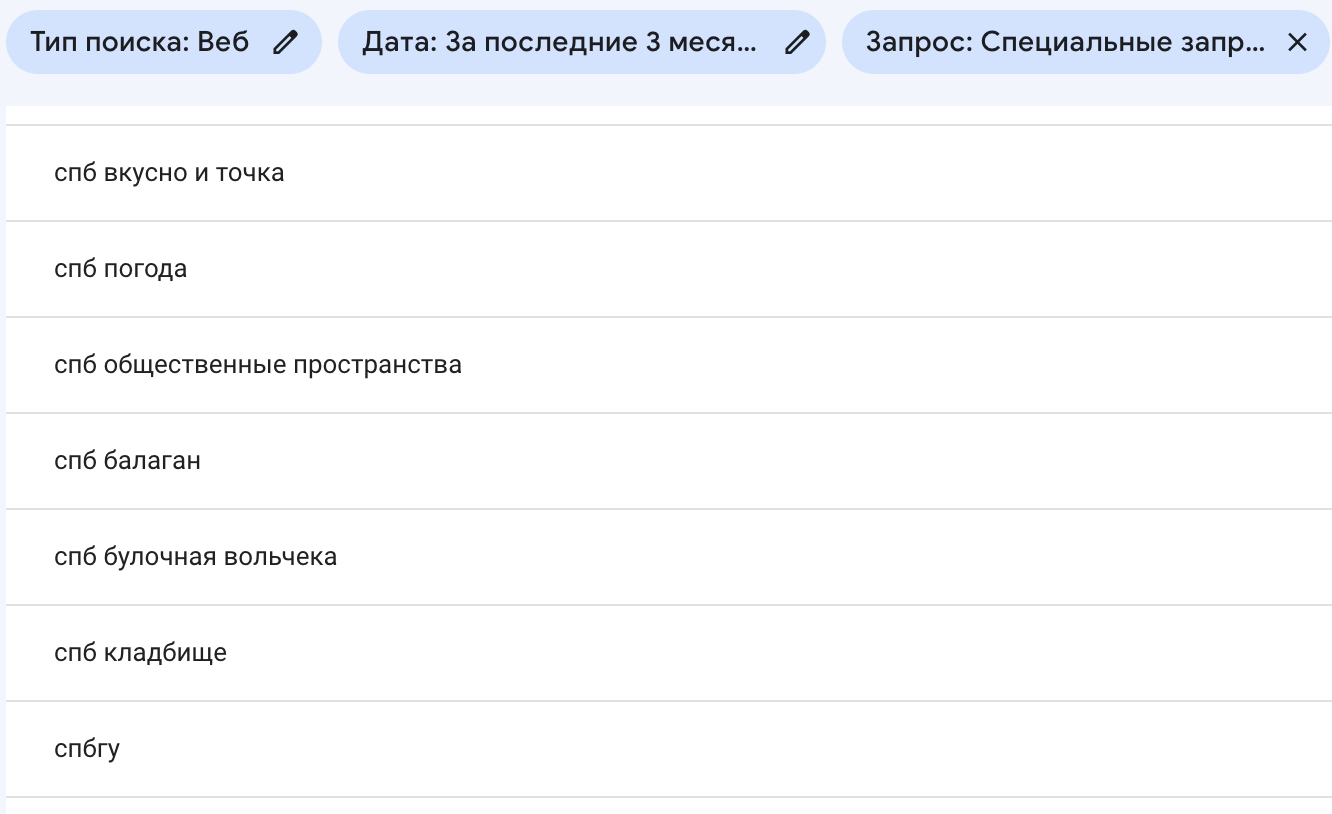
- Окончание строки — /$, где $ – символ окончания строки, а / — символ, которым должен оканчиваться адрес сайта;
- Кириллица — [а-я];
- Латиница — [a-z];
- Любой одиночный символ — .;
- Любая одна цифра — \d эквивалентно [0-9];
- Знак пробела — \s;
С полным списком регулярных выражений и синтаксисом можно ознакомиться на странице https://github.com/google/re2/wiki/Syntax.